https://www.boostcourse.org/ai215/lecture/355342
딥러닝 1단계: 신경망과 딥러닝
부스트코스 무료 강의
www.boostcourse.org
신경망은 무엇인가?
- 딥러닝: 신경망을 학습시키는 것.
- 신경망
ex) 주택 가격 예측 함수를 만든다고 하자. 선형 회귀에 입각하여 경향을 직선으로 표현한다. 이때 주택 가격은 음수가 될 수 없으므로 (0,0)부터 직선의 x절편까지는 0을 값으로 갖게 해 준다. 선을 꺾어 그리는 것이다. 이 주택가격을 예측하는 함수를 간단한 신경망으로 생각해볼 수 있다. x축인 주택의 크기가 입력이다. 입력은 작은 원으로 표현되는 노드로 들어간다. 이후 출력으로 나올 주택의 가격이 y값이다. 그 작은 원이 신경망에서의 하나의 뉴런이 된다. 이 원은 그 함수를 구현하게 된다.(하나의 뉴런 = 함수) 뉴런은 주택의 크기를 입력으로 받아 선형함수를 계산하고, 결과값과 0중 큰 값을 주택의 가격으로 예측해 출력한다. 이렇게 0으로 유지되다가 직선으로 올라가는 형식의 함수를 ReLu(Rectified Linear Unit)함수라고 한다. 더 큰 신경망은 더 많은 수의 뉴런으로 이루어져 있다.

뉴런이나 간단한 예측기들을 쌓아 올림으로써 더 큰 신경망을 형성한다.
- x 입력 4가지를 토대로 price라는 y값을 도출한다. 그 중간에 있는 뉴런들에서 어떤 일이 일어나기에 y값을 알아낼 수 있는 것일까? 그 중간의 뉴런들은 은닉 유닛이다. 입력층과 은닉 유닛은 조밀하게 연결되어 있다. 모든 입력 특성은 중앙에 있는 원 모두에 연결되어 있다. x와 y 예제를 많이 준다면, 신경망은 x를 y로 연결하는 함수를 알아내는 것을 잘 하게 될 것이다.
- 신경망이란 입력x와 출력y를 매칭해주는 함수를 찾는 과정이다. 이때 해당 뉴런에 관계없는 입력값이어도 입력으로 넣어주어야 한다.
신경망을 이용한 지도학습
- 지도학습(Supervised Learning)은 머신러닝의 한 종류이다.
- 지도학습에서는 인풋 x에 대한 아웃풋 y를 매칭하는 구조로 학습이 진행된다.
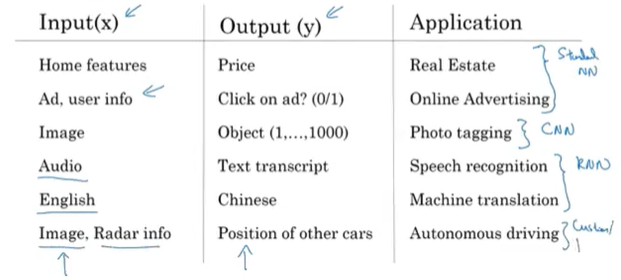
- 가장 많이 쓰이는 분야는 온라인 광고이다.
- 신경망을 통한 많은 값들의 생성은 어떤 문제를 해결하기 위한 적절한 x와 y를 통해 이루어진다.
- 활용 분야
- 온라인 광고: standard NN
- 언어 번역: 시퀀스 데이터. RNN의 조금 더 복잡한 버전들.
- 음성인식: 음성은 1차원의 시계열 데이터로 나타나는 시퀀스 데이터. RNN(순환 신경망)
- 자율주행(이미지, 레이더 정보를 통해 주변 도로 상황을 파악): CNN(이미지를 사용하는 경우), 그 외 복합적인 구
- 컴퓨터비전: CNN(Convolutional NN, 합성곱 신경망.)
- CNN과 RNN

RNN은 1차원 데이터에 강하다.
- 구조적 데이터(Structured Data) vs 비구조적 데이터(Unstructured Data)
- 구조적 데이터: 데이터베이스 형태로 표현된 데이터. 테이블 형태.
- 비구조적 데이터: 음성파일, 이미지 또는 텍스트. (비구조적 데이터의 feature: 이미지의 픽셀값, 텍스트의 각 단어.)
-> 비구조적 데이터가 인간이 이해하기에는 더 쉽지만, 컴퓨터에게는 구조적 데이터보다 훨씬 처리하기 어렵다.
-> 우리는 미디어에서 비구조적 데이터 신경망의 사례를 더 신기하게 받아들이지만, 신경망에서 발생하는 경제적 이익은 광고 시스템이나 사용자 맞춤 추천 같은 구조적 데이터에서 오는 경우가 많다.
왜 딥러닝이 뜨고 있을까요?
- Scale drives deep learning progress: Neural Network의 성능 그래프는 입력으로 주어지는 그 데이터의 수가 방대할수록 높아진다. 큰 NN일 수록 많은 데이터가 필요하다. 많은 양의 데이터를 이용하기 위해서는 충분히 큰 신경망이 필요하다. 데이터셋의 크기m이 아주 클 때만 large NN이 medium NN, small NN, Traditional learning algorithm(SVM, logistic regression,...) 등등 다른 방법을 압도하는 경향을 보인다.
-> Data, Computation, Algorithms의 발전. 더 큰 데이터를 사용하게 되었고, 컴퓨터 성능이 향상되었고, 알고리즘에도 혁신이 있었다.
- 알고리즘의 발전의 사례) sigmoid 함수 대신 ReLu 함수를 사용하게 된 것. sigmoid 함수는 왼쪽, 오른쪽 끝으로 가면 미분값이 0이 되기 때문에 Gradient가 소멸하는 문제가 발생한다. ReLu의 경우 미분결과가 0을 제외한 모든 x에 대해 상수로 떨어지므로 이 문제를 해결 가능.
- computation의 발전으로 인해 짧은 시간 안에 더 많은 algorithm의 성능을 시험해 볼 수 있게 되었다. 아이디어 생산 -> 코드 구현 -> 실험 결과 의 과정의 시간이 단축되었다.
'머신러닝' 카테고리의 다른 글
| [딥러닝] 딥러닝 1단계: 신경망과 딥러닝 - 2. 신경망과 로지스틱 회귀 (2/2) (1) | 2024.03.18 |
|---|---|
| [딥러닝] 딥러닝 1단계: 신경망과 딥러닝 - 2. 신경망과 로지스틱 회귀 (1/2) (0) | 2024.03.11 |
| 안드로이드 스튜디오에서 yolov8 커스텀 모델로 Object Detection 앱 만들기 (0) | 2023.11.24 |
| 안드로이드 스튜디오에서 mlkit로 object detection 구현하기 (1) | 2023.11.11 |
| [머신러닝] 혼자 공부하는 머신러닝 + 딥러닝 Chap.1 (1) | 2023.10.04 |