1. Google Colab에서 Yolov8로 원하는 데이터셋 학습하기
먼저 데이터셋을 준비한다. 나는 Roboflow의 Drowsiness Data를 사용했다.
https://universe.roboflow.com/ndthien150-gmail-com/drowsiness-dataset/dataset/2
Drowsiness dataset Object Detection Dataset (v2, 2022-10-28 9:01am) by ndthien150@gmail.com
3411 open source drowsiness-faces-detect images and annotations in multiple formats for training computer vision models. Drowsiness dataset (v2, 2022-10-28 9:01am), created by ndthien150@gmail.com
universe.roboflow.com
운전자의 졸음 여부를 판별할 수 있는 데이터셋이다. 직접 클래스별 이미지를 확인해본 결과 하품, 창 밖 주시 등의 부주의 운전의 신호들과 졸음운전 상태에 해당하는 이미지들이 있었고 총 9개의 클래스로 라벨링되어 있다.
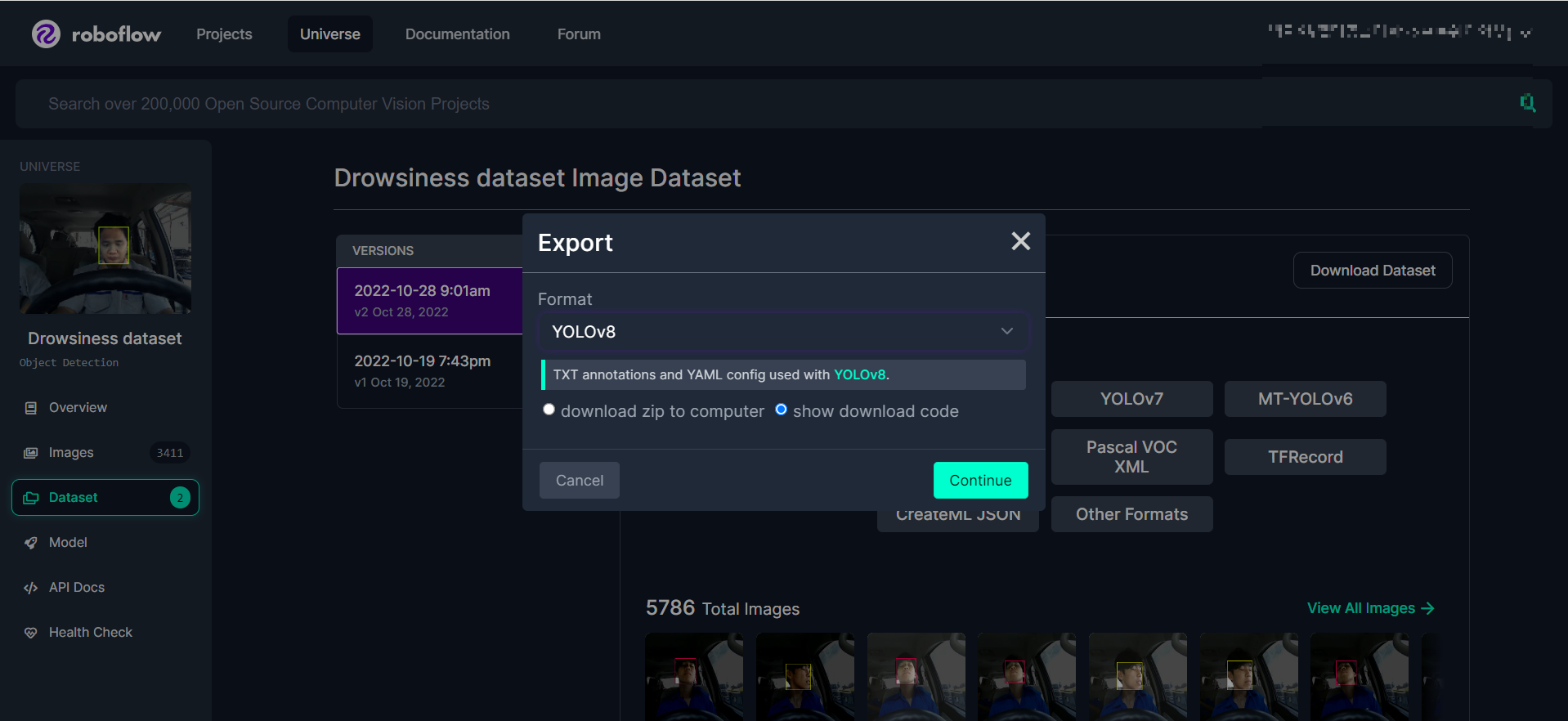
Download Dataset을 누르고 format에서 YOLOv8을 선택한다. 코랩에서 바로 다운받아 사용하기 위하여 show download code를 선택하고 continue를 클릭하면 다운로드 링크가 나온다.
google colab에서 다음 코드들을 입력한다.
!wget -O Drowsiness_Data.zip https://universe.roboflow.com/ds/jbn1G6TB3K?key=ro3ShB0Ve4
해당 데이터셋이 Drowsiness_Data.zip 이라는 이름으로 다운로드된다. 원하는 대로 설정해주면 된다.
import zipfile
with zipfile.ZipFile("/content/Drowsiness_Data.zip") as target_file:
target_file.extractall("/content/Drowsiness_data")
나는 google드라이브에 연결하지 않고 런타임 내에서 다운로드했다.
압축 해제 코드이다.
!cat /content/Drowsiness_data/data.yaml
Roboflow의 장점은 yaml파일이 제공된다는 점이다. 위 코드의 결과로 data.yaml에 저장되어 있는, 다운받은 데이터셋의 클래스 개수, 클래스 이름이 출력된다.
!pip install PyYAMLimport yaml
data = { 'train' : '/content/Drowsiness_data/train/images/',
'val' : '/content/Drowsiness_data/valid/images/',
'test' : '/content/Drowsiness_data/test/images',
'names' : ['head-down sleep', 'yawn', 'in-place sleep', 'head-up sleep', 'passenger-toward sleep', 'looking at passenger seat', 'in-place non-sleep', 'window-toward sleep', 'looking at window'],
'nc' : 9 }
with open('/content/Drowsiness_data/Drowsiness_data.yaml', 'w') as f:
yaml.dump(data, f)
with open('/content/Drowsiness_data/Drowsiness_data.yaml', 'r') as f:
drowsiness_yaml = yaml.safe_load(f)
display(drowsiness_yaml)
yaml파일의 train, valid, test 이미지 파일의 절대주소와 클래스 names목록을 수정해 주었다. 중요한 단계다.
!pip install ultralytics
import ultralytics
ultralytics.checks()
yolo 모델을 오픈소스로 제공하는 ultralytics를 임포트한다.
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
나는 yolov8 중에서 yolov8n을 사용한다.
print(type(model.names), len(model.names))
print(model.names)
해당 모델의 기본 객체들이 출력된다. 자전거, 시계, 곰인형 등등...기본적인 일상적인 클래스들이다. 이를 커스텀 학습을 통해 내가 탐지하고자 하는 9개의 클래스를 표시하도록 재학습 시킬 것이다.
model.train(data = '/content/Drowsiness_data/Drowsiness_data.yaml', epochs=15, patience=30, batch=32, imgsz=416)
epochs(전체 데이터셋을 학습하는 횟수)를 적절하게 선택한다. batch는 1 epoch당 데이터를 쪼갠 조각의 수이다. 낮으면 정확도가 오르지만 시간이 오래 걸린다.
https://m.blog.naver.com/qbxlvnf11/221449297033
머신 러닝 - epoch, batch size, iteration의 의미
- 출처 이번 포스팅의 주제는 텐서플로우나 케라스 등을 사용해서 모델을 만들어 보았으면 다들 아실 용어...
blog.naver.com
의미에 대해서는 이 블로그 글을 참고하자.
model train은 시간이 오래 걸린다. colab에서 실행할 때 꼭 런타임 유형을 GPU인지 확인한 후 하도록 하자. 세션 중간에 유형을 변경하게 되면 지금까지 런타임 내에서 저장한 파일과 코드 결과들이 모두 날아가니 시작하기 전 처음에 확인한다.
Model summary (fused): 168 layers, 3007403 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:08<00:00, 1.24it/s]
all 680 680 0.977 0.962 0.989 0.939
head-down sleep 680 67 0.984 1 0.991 0.843
yawn 680 62 0.985 0.968 0.995 0.966
in-place sleep 680 150 0.992 0.993 0.995 0.973
head-up sleep 680 78 0.976 0.987 0.994 0.925
passenger-toward sleep 680 40 1 0.825 0.966 0.926
looking at passenger seat 680 55 0.916 0.988 0.984 0.955
in-place non-sleep 680 145 0.992 0.993 0.995 0.98
window-toward sleep 680 37 0.95 0.946 0.99 0.934
looking at window 680 46 0.996 0.957 0.988 0.946
Speed: 0.1ms preprocess, 1.3ms inference, 0.0ms loss, 2.2ms postprocess per image
Results saved to runs/detect/train
실행 결과를 가져왔다. Yolo 모델의 정확도는 mAP으로 확인할 수 있다. 간단하게 설명하면 mAP50-95가 mAP50보다 엄격한 기준이다. 그렇지만 mAP50이 0.99인 걸로 봐서 학습은 꽤 잘 된 걸 알 수 있다.
print(type(model.names), len(model.names))
print(model.names)
실행결과:
<class 'dict'> 9 {0: 'head-down sleep', 1: 'yawn', 2: 'in-place sleep', 3: 'head-up sleep', 4: 'passenger-toward sleep', 5: 'looking at passenger seat', 6: 'in-place non-sleep', 7: 'window-toward sleep', 8: 'looking at window'}
내가 설정한 클래스대로 잘 train되었다.
results = model.predict(source = '/content/Drowsiness_data/test/images/', save=True)
test 데이터셋에 대해 predict한다.
print(results[0])
print()
print(results[0].boxes)from google.colab.patches import cv2_imshow
res_plotted = results[26].plot()
cv2_imshow(res_plotted)
google.colab.patches의 cv2_imshow를 임포트하면 opencv의 imshow 함수를 코랩에서 사용할 수 있다.
이를 이용하여 학습한 모델이 test데이터셋의 이미지들을 잘 predict했는지 화면에 보일 수 있다.
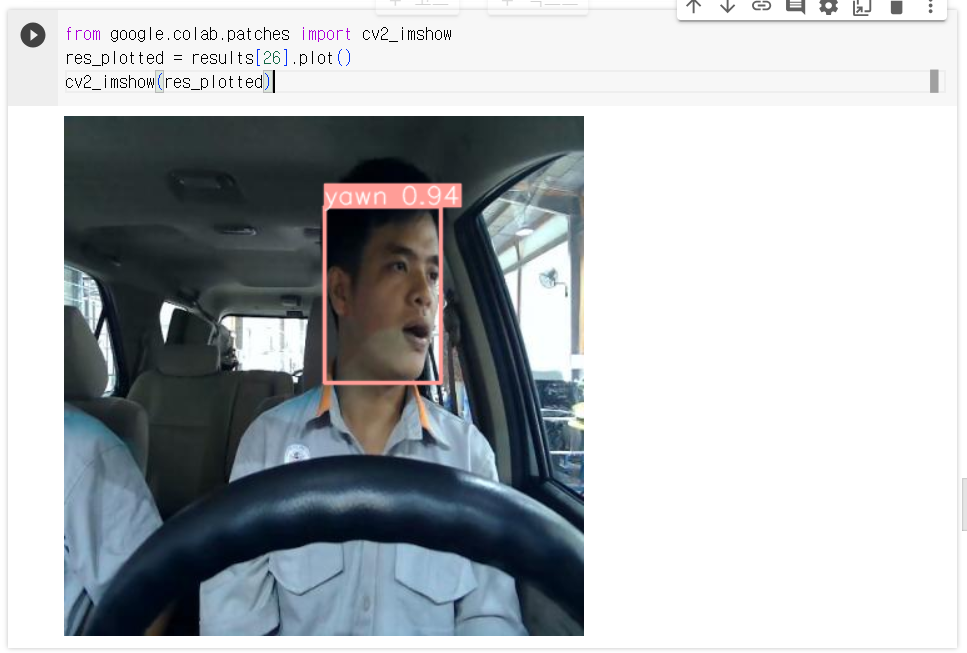
나의 목표는 하품 여부를 가려내는 모델을 만드는 것이므로 yawn 클래스에 해당하도록 predict된 result를 출력해 봤다.
0.94의 높은 확률로 yawn 클래스의 객체로 탐지된 것을 확인할 수 있다.
results2 = model.predict(source = '/content/test data/', save=True)
Roboflow에서 제공한 test 데이터셋 외에 내가 직접 촬영한 사진으로도 detection이 잘 되는지 알아보기 위해 코랩에 test data라는 폴더를 만들고 내 사진 두 장을 업로드해 새로운 predict를 진행했다.
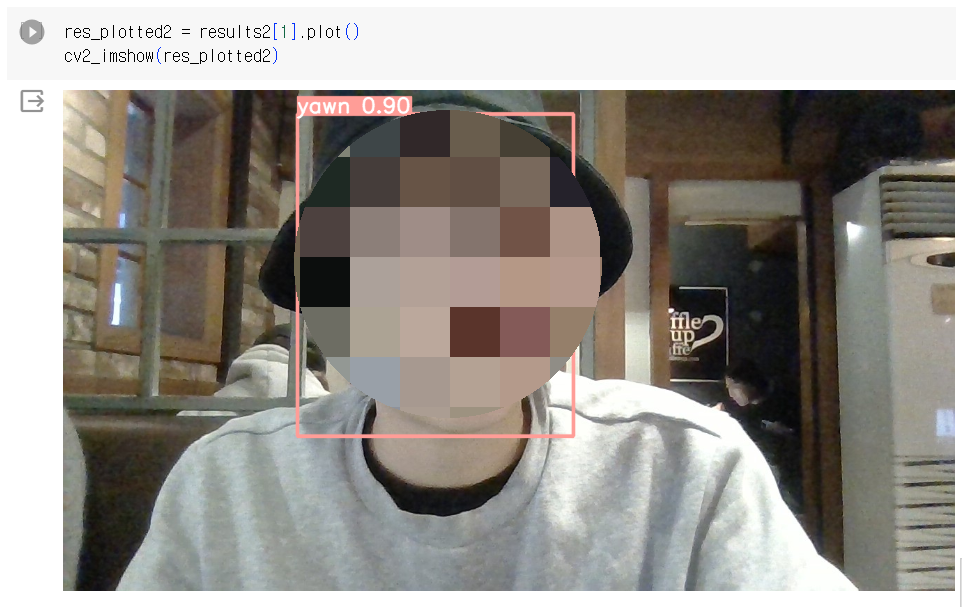
^^;
잘 탐지가 되는 것을 확인할 수 있었다.
model로 train을 완료하면, runs 폴더 내의 weights 파일에 best.pt 파일이 생성된다. 해당 파일이 바로 이 모델의 weight이다. 이 모델의 weight가 저장되어 있는 파일로 핵심 정보가 들어있다고 할 수 있다. 가장 성능이 좋았을 때의 weight가 저장된다.
여기까지 원하는 데이터셋을 YOLOv8로 train하는 방법에 대해 알아보았다.
2. 안드로이드 스튜디오에 YOLOv8 커스텀 모델 플러그인하기
Tensorflow Lite에서 제공하는 Object detection 데모 앱을 이용하면 커스텀 모델을 안드로이드 앱에서 구동할 수 있다.
https://github.com/googlecodelabs/odml-pathways/archive/refs/heads/main.zip
위 zip파일을 다운받아 압축을 해제한다.
object-detection/codelab2/android 저장소의 starter 를 Android Studio에서 연다.
툴바에서 Sync Project with Gradle Files을 선택하면 프로젝트를 Gradle파일과 동기화할 수 있다.
- fun runObjectDetection(bitmap: Bitmap) 미리 설정된 이미지를 선택하거나 사진을 찍으면 이 메서드가 호출됩니다. bitmap는 객체 감지를 위한 입력 이미지입니다. 이 Codelab의 뒷부분에서 이 메서드에 객체 감지 코드를 추가합니다.
- data class DetectionResult(val boundingBoxes: Rect, val text: String) 시각화를 위한 객체 감지 결과를 나타내는 데이터 클래스입니다. boundingBoxes는 객체가 있는 직사각형이고 text는 객체의 경계 상자와 함께 표시할 감지 결과 문자열입니다.
- fun drawDetectionResult(bitmap: Bitmap, detectionResults: List<DetectionResult>): Bitmap 이 메서드는 입력 bitmap의 detectionResults에 객체 감지 결과를 그리고 수정된 복사본을 반환합니다.
다음은 drawDetectionResult 유틸리티 메서드의 출력 예입니다.

전체적인 작동 과정은 위와 같다.
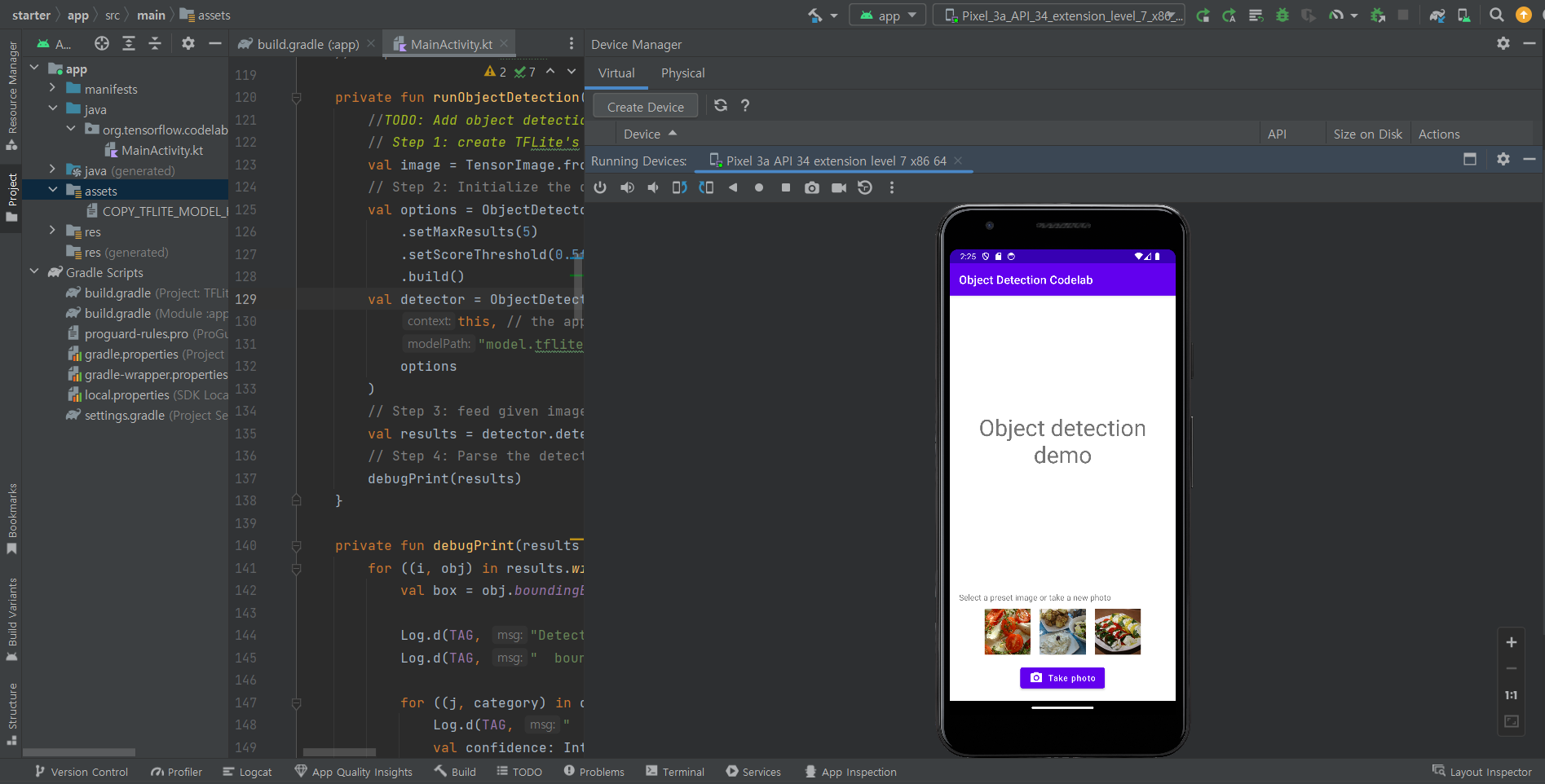
처음 들어가서 아무것도 건드리지 않고 build 후 가상 안드로이드 기기에 연결하면 다음과 같은 화면이다.
이제 원하는 모델을 앱에서 구동할 수 있도록 코드 몇 줄을 Mainactivity.kt에 추가해야 한다.
그 전에, 1번에서 학습했던 모델의 best.pt파일을 tensorflow에서 활용할 수 있도록 .tflite 형식으로 변환해 주는 과정이 필요하다. 그런 후에는 단훈히 assets 폴더 밑에 넣어 주기만 하면 되나, 이 변환과정이 꽤나 골치아팠다.
다시 코랩으로 돌아가서,
!python export.py --weights runs/train/exp/weights/best.pt --include tflite --img 416
위 코드의 runs/train/exp/weights/best.pt 부분에 best.pt의 주소를 넣으면 된다.
이때 이 과정은 모델 학습 후 런타임이 끊기지 않은 상태에서 진행해야 한다. 나는 한 번에 진행해서 수월했지만, 작업을 한 번에 수행하는 게 아닌 경우 구글드라이브에 모델을 저장해 두는 것이 훨씬 편할 것이다.
또는, 먼저 .pt를 .onnx로 바꾼 뒤 온라인 무료 변환 사이트를 이용해서 .onnx를 .tflite로 바꾸는 방법도 있다.
https://launchx.netspresso.ai/main
다시 안드로이드 스튜디오로 돌아와서,
얻은 .tflite파일을 assets 폴더에 복사하고 이름을 model.tflite로 지정한다.
app/build.gradle 파일의 dependenceis에 다음 코드를 추가한다. 라이브러리 종속 항목 업데이트 코드다.
implementation 'org.tensorflow:tensorflow-lite-task-vision:0.3.1'
'
지금부터는 MainActivity.kt 파일을 수정하여 이미지에서 객체를 감지할 수 있도록 설정할 것이다.
runObjectDetection(bitmap: Bitmap) 함수를 수정한다.
/**
* TFLite Object Detection Function
*/
private fun runObjectDetection(bitmap: Bitmap) {
//TODO: Add object detection code here
}// Step 1: create TFLite's TensorImage object
val image = TensorImage.fromBitmap(bitmap)
위 코드는 사용할 이미지 객체를 만든다.
// Step 2: Initialize the detector object
val options = ObjectDetector.ObjectDetectorOptions.builder()
.setMaxResults(5)
.setScoreThreshold(0.5f)
.build()
val detector = ObjectDetector.createFromFileAndOptions(
this, // the application context
"model.tflite", // must be same as the filename in assets folder
options
)
위 코드는 검사 프로그램 인스턴스를 만든다. 객체 감지기의 민감도를 조정하는 옵션을 비롯하여 몇 가지 옵션을 구성한다.(최대 결과, 점수 임계값, 라벨 허용 목록/거부 목록)
모델 파일명이 실제 파일명과 일치하도록 주의하자.
// Step 3: feed given image to the model and print the detection result
val results = detector.detect(image)
위 코드는 이미지를 검사 프로그램에 전달한다.
// Step 4: Parse the detection result and show it
debugPrint(results)
완료되면 감지기는 Detection목록을 반환한다. 각 목록에는 모델이 이미지에서 발견한 객체에 대한 정보가 포함된다.
- boundingBox: 이미지 내에서 객체의 존재와 위치를 선언하는 직사각형
- categories: 객체의 종류 및 감지 결과에 대한 모델의 신뢰도입니다. 이 모델은 여러 카테고리를 반환하고 가장 신뢰도 높은 카테고리를 먼저 반환합니다.
- label: 객체 카테고리의 이름입니다.
- classificationConfidence: 0.0~1.0 범위의 부동 소수점 수, 1.0: 100%
private fun debugPrint(results : List<Detection>) {
for ((i, obj) in results.withIndex()) {
val box = obj.boundingBox
Log.d(TAG, "Detected object: ${i} ")
Log.d(TAG, " boundingBox: (${box.left}, ${box.top}) - (${box.right},${box.bottom})")
for ((j, category) in obj.categories.withIndex()) {
Log.d(TAG, " Label $j: ${category.label}")
val confidence: Int = category.score.times(100).toInt()
Log.d(TAG, " Confidence: ${confidence}%")
}
}
}
마지막으로 위 debugPrint()메서드를 MainActivity 클래스에 추가한다.
이제 프로젝트를 build하면 object detection이 실행된다. Logcat에서 객체탐지 현황을 확인한다.
val resultToDisplay = results.map {
// Get the top-1 category and craft the display text
val category = it.categories.first()
val text = "${category.label}, ${category.score.times(100).toInt()}%"
// Create a data object to display the detection result
DetectionResult(it.boundingBox, text)
}
// Draw the detection result on the bitmap and show it.
val imgWithResult = drawDetectionResult(bitmap, resultToDisplay)
runOnUiThread {
inputImageView.setImageBitmap(imgWithResult)
}
위 코드를 MainActivity.kt에 추가하면 입력 이미지 위에 바운딩 박스와 탐지한 객체의 이름이 출력된다.
지금까지 안드로이드 스튜디오 개발환경에서 TF Lite를 이용해 커스텀 Object detection 모델을 구동시켜 보았다.
'머신러닝' 카테고리의 다른 글
| [딥러닝] 딥러닝 1단계: 신경망과 딥러닝 - 2. 신경망과 로지스틱 회귀 (2/2) (1) | 2024.03.18 |
|---|---|
| [딥러닝] 딥러닝 1단계: 신경망과 딥러닝 - 2. 신경망과 로지스틱 회귀 (1/2) (0) | 2024.03.11 |
| [딥러닝] 딥러닝 1단계: 신경망과 딥러닝 - 1. 딥러닝 소개 (0) | 2024.03.11 |
| 안드로이드 스튜디오에서 mlkit로 object detection 구현하기 (1) | 2023.11.11 |
| [머신러닝] 혼자 공부하는 머신러닝 + 딥러닝 Chap.1 (1) | 2023.10.04 |