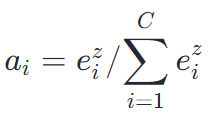자연어 처리 개요자연어 처리 활용 분야와 트렌드Task- Natural Language Understanding(NLU): 컴퓨터가 주어진 단어, 문단을 이해하는 것- Natural Language Generation(NLG): 자연어를 상황에 따라 적절히 생성하는 것활발하게 연구되고 있는 분야. 분야- NLP: 딥러닝 분야 발전 선도학회: ACL, EMNLP, NAACL- NLP task: low-level parsing(문장을 토큰 단위로 나누고 단어의 원형을 찾는 것 의미레벨), Word and phrase level(Named entity recognition, part-of-speech tagging품사, noun-phrase chunking, dependency parsing, dorefere..